Deterministic or Probabilistic? The Clinical AI Distinction Every Clinician Should Understand

Dr. Neil Panchal
Chief Medical Officer
Share:

Understanding the distinction between deterministic and probabilistic AI is foundational to evaluating any clinical AI tool responsibly. It is also the single clearest lens for separating marketing from medicine in a field now crowded with “AI-powered” platforms promising clinical-grade outputs.
The good news: once the distinction is clear, evaluating these tools becomes straightforward. Every clinician, procurement officer, and patient-safety committee gains a reliable framework for asking the right questions before a single recommendation reaches a patient.
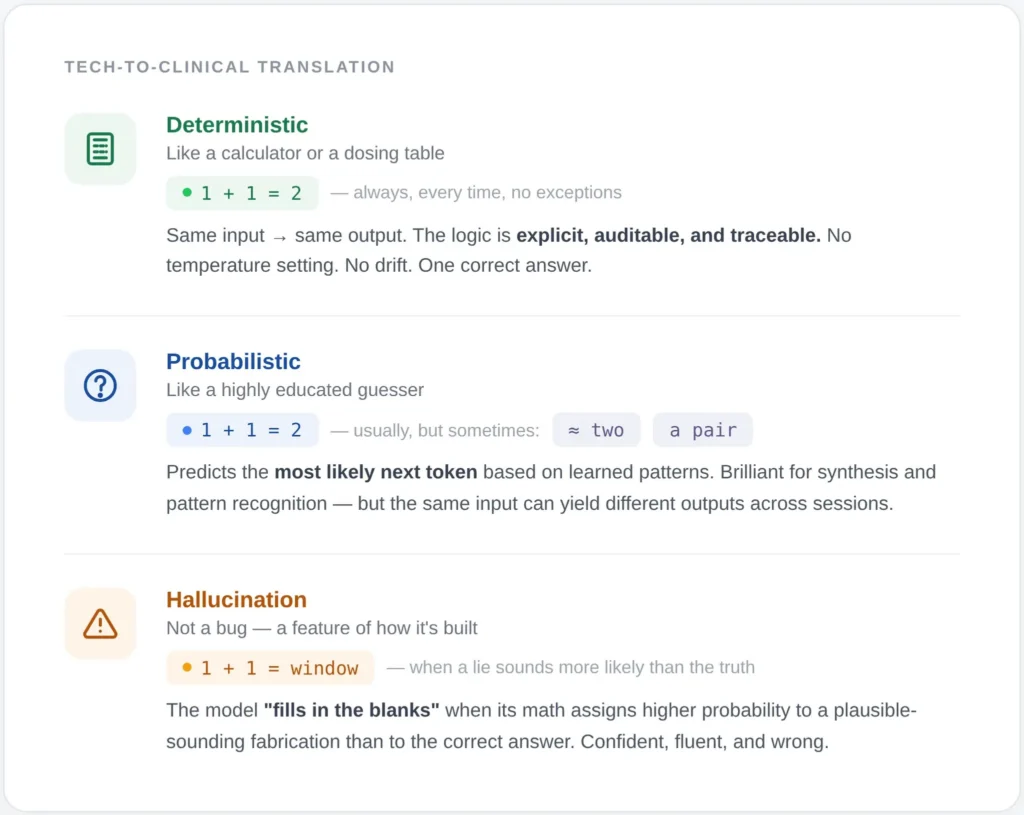
The Core Distinction
A deterministic AI system produces the same output for the same input, every time. Its logic is explicit, auditable, and traceable. If a patient’s LDL-C is 165 mg/dL, their ApoB is 130 mg/dL, and their Lp(a) is elevated, a deterministic system applies codified clinical rules and returns an identical stratification and recommendation across ten runs, ten clinicians, and ten patients with identical inputs. There is no drift, no sampling, no temperature setting. (Temperature—the setting that controls how ‘creative’ or random the AI is—doesn’t exist in deterministic systems because there is only one correct answer.)
A probabilistic AI system, the category that includes every large language model in clinical use, generates outputs by sampling from learned distributions. Think of it like a very sophisticated ‘autocomplete.’ It isn’t looking up a textbook; it’s predicting the most likely next word based on patterns it saw during training. The same input can yield meaningfully different outputs across sessions. The model does not “know” a fact; it estimates the most likely next token. This architecture is extraordinary for synthesis, summarization, and pattern recognition across unstructured data. It is also the mechanistic origin of hallucination. Probabilistic AI is like a brilliant intern reading through 500 pages of messy handwritten notes and faxes (unstructured data) to find a mention of a rare allergy. It’s a finder, not a decider.
Hallucination Is Not a Rounding Error
Recent peer-reviewed data make the stakes concrete.
A 2025 multi-model assurance analysis published in Communications Medicine tested leading LLMs in clinical decision support using physician-validated vignettes. When a single fabricated detail was embedded in a prompt, hallucination rates ranged from 50% to 83% across models. Prompt engineering reduced the rate but never eliminated it. No model was immune.
A comprehensive 2025 review of medical hallucination in foundation models reported that state-of-the-art medical LLMs exhibit hallucination rates between 15% and 40% on clinical tasks, with errors often arising from reasoning failures rather than knowledge gaps. Even domain-tuned models produced plausible-sounding fabrications that a non-expert reader could not flag.
The npj Digital Medicine framework published in May 2025 evaluating LLM-generated clinical notes documented a 1.47% hallucination rate and 3.45% omission rate across nearly 13,000 clinician-annotated sentences, even in a system deliberately engineered for safety. Those are best-case numbers in a controlled documentation task, not in open-ended diagnostic reasoning.
A probabilistic engine can be brilliant 97% of the time and still deliver a dangerous recommendation on the next case. In longevity and preventive medicine, where interventions compound across years and where the patient is often asymptomatic at the moment of decision, that variance is not a rounding error. It is the entire risk surface.
The Case for Deterministic Logic at the Clinical Core
Clinical guidelines already function deterministically. A drug-drug interaction alert, a contraindication flag, a dosing rule adjusted for eGFR — these are IF-THEN structures encoded from decades of evidence. When properly implemented, they behave identically for every patient who meets the criteria. That reproducibility is precisely what makes them defensible under clinical governance, medicolegal review, and regulatory scrutiny.
The 2026 npj Digital Medicine commentary on Unconfined Non-Deterministic Clinical Software makes this explicit: regulators across the FDA, EU, Australia, and Singapore treat deterministic and probabilistic clinical software differently precisely because their failure modes differ. Deterministic systems fail predictably. Probabilistic systems fail in ways that can be difficult to detect and impossible to reproduce for audit.
A January 2026 paper in Frontiers in Digital Health on AI-augmented clinical reasoning proposes the architecture that serious clinical AI should converge on: a deterministic, evidence-based clinician-facing layer — often implemented via Bayesian updating over validated guidelines — paired with probabilistic back-end modules that handle pattern recognition over unstructured data. The clinician sees reproducible output. The probabilistic component does what it is genuinely good at, behind a deterministic checkpoint.
Five Questions Every Vendor Should Answer
Five questions separate a defensible system from a marketing claim:
- Which layer produces the recommendation the clinician sees? If the final output is generated directly by an LLM, the recommendation inherits LLM variance and hallucination risk.
- Is the reasoning path traceable to a specific clinical rule, guideline, or published threshold? If the answer involves phrases like “the model inferred,” the output cannot be audited.
- Does identical input produce identical output across sessions? Run the same case three times. If the recommendation shifts in substance, the tool is probabilistic at the decision layer.
- Where is the LLM actually doing work? Synthesis of a patient narrative, extraction from lab reports, and literature retrieval are legitimate LLM use cases. Dosing, stratification, and intervention selection are not.
- What is the mechanism for updating the logic when guidelines change? Deterministic systems update by rule revision with version control. Probabilistic systems drift with retraining in ways clinicians cannot see.
The Architecture Longevity Medicine Requires
Longevity medicine sits at an unusual intersection. The data inputs are extensive — genomics, advanced lipidology, inflammatory panels, hormonal profiles, continuous biomarkers, imaging — and the intervention windows are long. A recommendation to modulate a metabolic pathway, initiate a peptide protocol, or adjust hormone replacement is consequential over years, not hours.
This domain demands a hybrid architecture in which probabilistic AI accelerates the work it excels at — ingesting heterogeneous data, surfacing patterns across thousands of patients, synthesizing literature — while a deterministic engine governs every output that touches a clinical decision. The clinician-facing logic should be reducible to explicit rules, grounded in published evidence, versioned, auditable, and identical in its behavior from one patient to the next.
That is not a limitation on AI. It is the condition under which AI becomes clinically trustworthy.
The most important question to ask of any clinical AI platform is not how sophisticated its model is. It is whether the recommendation a clinician acts upon is reproducible, traceable, and governed by explicit clinical logic. Everything else is optimization around that core requirement.
FAQ
Is deterministic AI the same as a decision tree or rule engine? Rule engines and decision trees are subsets of deterministic AI. The broader category also includes Bayesian networks operating over fixed priors, formal ontologies, and constraint-based reasoners. The defining property is reproducibility of output given identical input, not the specific implementation.
Can probabilistic AI ever be safe for clinical use? Yes, when bounded correctly. Probabilistic models perform well in tasks like document summarization, information extraction, and literature synthesis, particularly when paired with retrieval-augmented generation and a deterministic checkpoint before any clinical recommendation reaches the patient. The failure mode is using LLMs as the decision layer itself.
Does FDA clearance address this distinction? Partially. The 2025 update to FDA Software as a Medical Device guidance treats CDS tools according to intended use and end user. Systems that produce opaque recommendations without traceable rationale face stricter scrutiny than those exposing their logic. By mid-2025, over 1,250 AI-enabled medical devices had been authorized, the majority via 510(k), but clearance alone does not guarantee the architecture is deterministic at the decision layer.
What hallucination rate is acceptable in clinical AI? For any output that directly influences a clinical decision, the defensible answer is zero. Published hallucination rates in medical LLMs range from approximately 1.5% in controlled summarization tasks to over 80% under adversarial conditions. That variance alone argues against placing a probabilistic engine at the decision layer.
How should clinicians evaluate a new AI platform being introduced into their practice? Request a reproducibility test. Submit the same anonymized case three times across separate sessions and compare the recommendations. Request documentation of the reasoning path for a specific output. Ask which module generated the clinical recommendation and whether its logic is human-readable. A vendor unable or unwilling to answer these questions has answered them.
Where is probabilistic AI most valuable in longevity medicine? In ingestion and synthesis. Parsing unstructured lab reports, summarizing a patient’s multi-year record, surfacing relevant literature, and detecting patterns across cohorts are all tasks where probabilistic models add genuine value. The distinction is architectural: these functions should feed a deterministic engine that produces the clinical recommendation, not replace it.


